This year I tried to do a little more cycling during the week. I have a road bike, so I’m interested in quality roads – good tarmac, no potholes, enough shoulder to allow trucks to overtake me and live to talk about it. But I don’t know all roads around Bucharest. Best roads for biking are the smaller ones, with little traffic, that lead nowhere important. How can I find them?
I’ve worked on Strava data before and I saw here an opportunity to do it again. Using this simple script, I downloaded (over the course of several days) a total of 6 GB of GPS tracks. I started with the major Strava bike clubs in Bucharest, took all their members, then fetched all rides between April and the middle of June. Starting from 9 clubs, I looked over 1414 users. Only 674 have biked during the analyzed period. The average number of rides for those two and a half months was 25, with the [10, 25, 50, 75, 90]-percentile values of [2, 6, 17, 36, 64]. These are reasonable values, considering there are people that are commuting by bike (even over 20 km per day).
Ok, how can you determine the road quality from 6 GB of data? Simplest solution: take the speed every second (you already have that from Strava) and put it on a map. I did this by converting (lat, lng) pairs to (x, y) coordinates on an image. Each pixel was essentially a bucket, holding a list of speed values.
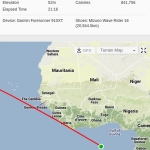
Let’s check out the area around Bucharest (high res version available here):
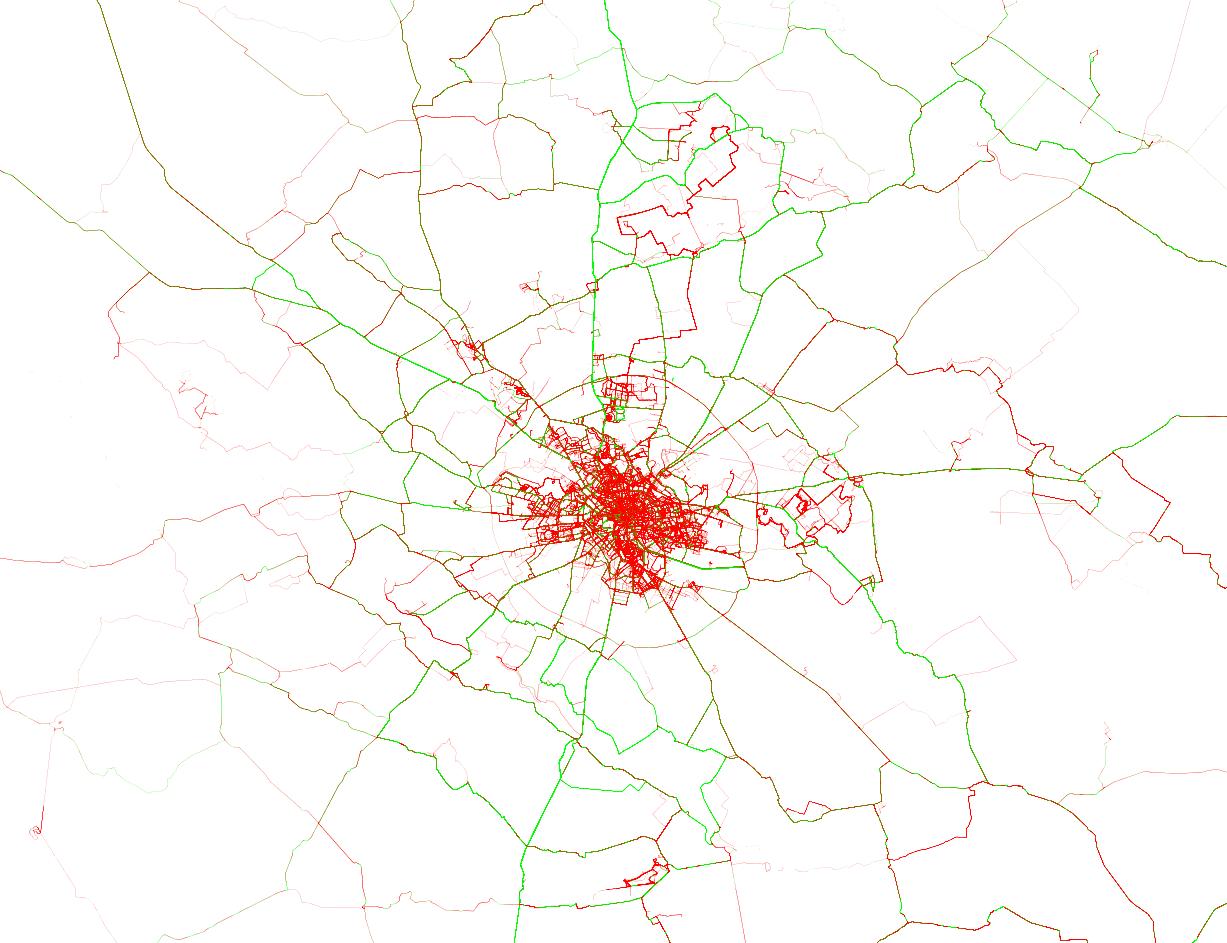
In this chart, bright green lines signal roads where there are many riders going over 35 kmph (technically speaking, the 80th percentile is at 35). On the opposite side, red roads are those where you’ll be lucky going with 25 kmph. The color intensity signals how popular a route is, with rarely used roads being barely visible. I already knew the good roads north of Bucharest, with Moara Vlasiei, Dascalu, Snagov and Izvorani. I saw on Strava that the SE ride to Galbinasi is popular, but I’ve never ridden it. From this analysis, I can see there are many good roads to the south and a couple of segments to the west. Unfortunately for me, for anything that’s not in the north I have to cross Bucharest, which is a buzzkill. Also notice the course from Prima Evadare (the jagged red line in the north) and the MTB trails in Cernica, Baneasa and Comana.
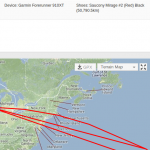
Let’s zoom in a little and see how the city looks like:
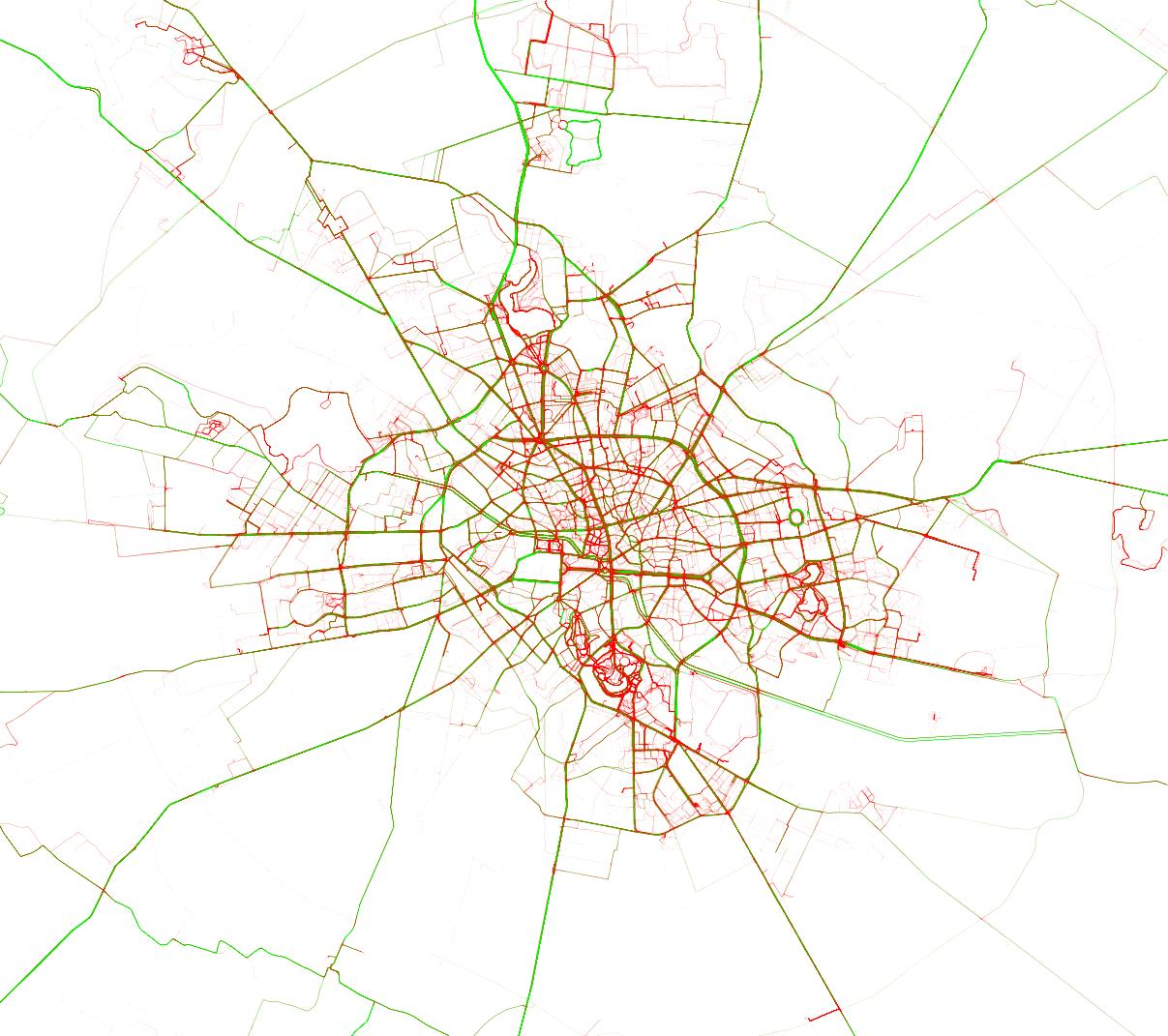
For this chart, I relaxed the colors a little, with 35 kmph for green and only 20 kmph for red. Things to notice:
- the RedBull MoonTimeBike course in Tineretului (in red); notice that the whole of Tineretului or Herastrau are red; it means you can’t (and shouldn’t) bike fast in parks; please don’t bike fast in parks, it’s unpleasant (and dangerous) for bikers and pedestrians alike
- the abandoned road circuit in Baneasa (in bright green)
- National Arena in green
- the two slopes around The People’s Palace in green (from how it’s built, all slopes will be green, which is not a problem, since Bucharest is pretty much flat)