I’ve been running a little more seriously this year. On Strava, I’ve registered 427km, including a few contests: EcoMarathon (14km +600m), San Francisco Marathon (41km), Golden Gate Trail Run (30km, +1200m) and Piatra Craiului Marathon (38km, +2300m). During these races I’ve noticed I’m really slow – finishing somewhere in the last 10% – 20% in my category. So the questions that emerged in my mind were:
– taking training out of the equation, am I just slower than others?
– how important is training in improving my running pace? If I trained more, how much should I expect to improve?
Analysis Procedure
I chose as reference the personal record over 10 kilometers. I would get this info about a bunch of users, along with how much they’ve run this year. I would remove users that are new to Strava – since I can’t determine if they just started running of if they just started using Strava, yet having already ran a lot.
Having this data, I would see how much the 10k time improves as an athlete trains more. I would also see how I stand compared to other having similar training and how much I can expect to improve, given more training.
Getting the Data
First off, let’s get some data out of Strava, so I have people to compare myself to. Since Strava doesn’t have a public API, I had to scrape their website. I got a list of users from a monthly running challenge. Scraping here was straightforward – the call didn’t require authentication and gave data in JSON. In the end, I had 17000 ids for active Strava users.
Then, I needed some statistics on each user. Since those statistics required authentication, I used a script that handled all that, so I could access the site from within Python. Worked a little more on getting the data out of HTML format.
After removing users that started using Strava recently, I was left with around 7000 data points. I also had to remove users having erroneous GPS tracks – appears Garmin has a bug that sometimes sends you to the point with coordinates (0, 0):
-
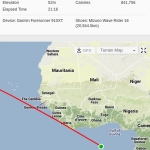
- Running across the Atlantic
-
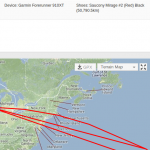
- Running across the Atlantic.. thrice
I also removed people that were very slow. If you need more than 2 hours for 10km, you’re walking. And you’re also messing up my chart.
Analysis
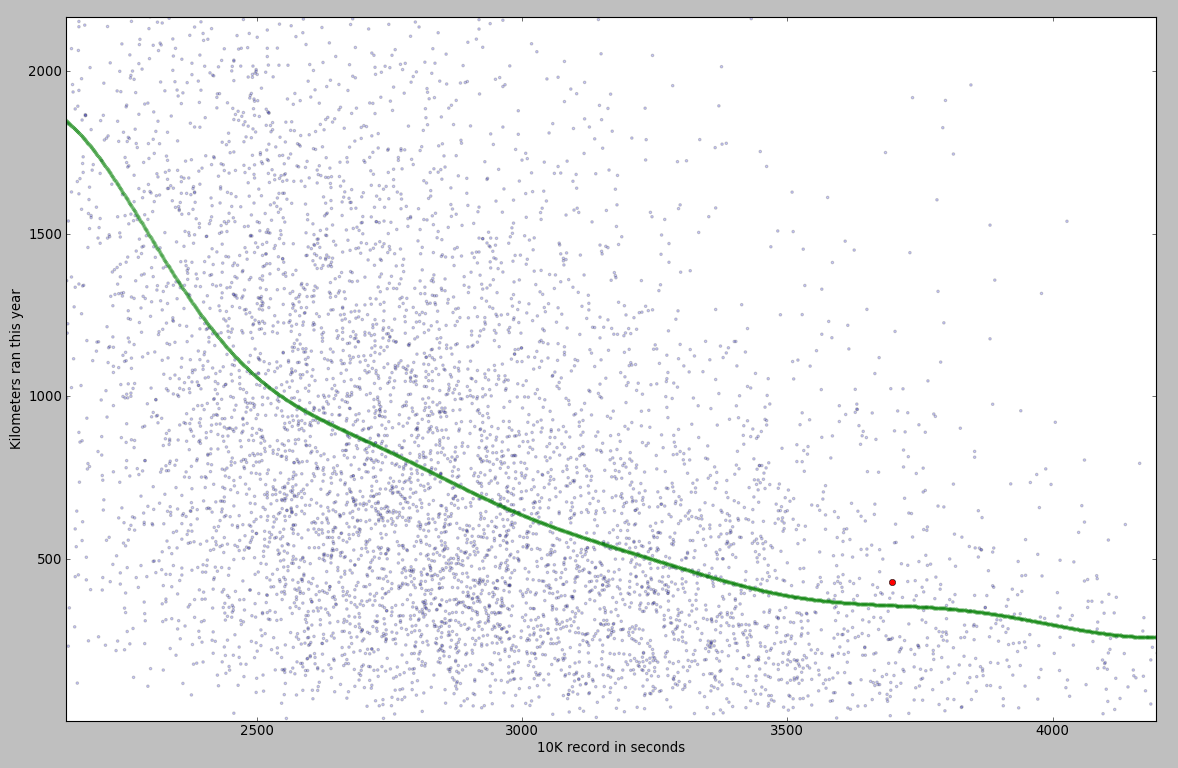
I put all the points on a scatter plot. I trained an SVR on them, so I could also show a pretty line (in green). You can see my record on the chart as a red point.
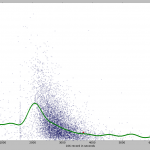
You can see some fishy stuff on the chart. The fishiest is the group of points very similar to the 10k World Record (26:17 or 1577 seconds). I looked over a couple of the tracks that generated those points and they seem to be mislabeled bike rides. Yet, I can’t explain why there are so many points around the world record value. Most likely a Strava bug.
There are a lot of people faster than the World Record. Some of them are going up to over 500 kmph. Mislabeled… flight?
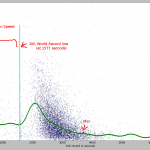
Let’s zoom on the area with the highest concentration of points. It looks like this:
What you can notice from this chart:
– if you train more, you get faster. The improvement is not linear – it takes more training to improve the better you become;
– I am indeed slower than other people with similar training.
The SVR model estimated an average runner, having the same training as me, would be 5 minutes faster. Another result from the model: I would need 867km of running in order to reach a time of 50 minutes. Hmm… seems science is telling me to move on to a new sport.
This is really fascinating. I developed a site called smashrun.com, and one of the the things I things I think that’s really interesting that we do is calculating percentile rank across various metrics, speed at various distances, but also distance run and days run/not run. For an example you can see my results here: http://smashrun.com/chris.lukic/medals/speed
I’ve wanted to do some analysis similar to what you’ve done here with improvement vs training load, but as always finding the time is a challenge.
One of the things I can say is that filtering out the outliers is really challenging, there’s just not much difference between the performance of a slow bike rider and world class runner, and while you can be reasonable sure that the sub 30 minute 10ks are bike rides, what you can’t be sure of is how many of the 40 and 50 minute 10ks are “slow” bike rides. Not to mention all of the people with uncalibrated Nike chips, or even more likely mobile apps with dubious recordings. But I think most people have an interest in getting their data right, and to a large effect the errors tend to wash out one another in both directions, I hope…
On smashrun a 1 hour 10k time puts you right at about the 25th percentile. But from the looks of it you’re running some serious elevation. Most of these record 10ks are done on a straight flat with a tail wind. And that alone could make a huge difference. All you need to do is run 1k/hr to be in the 50th percentile, and a few hills can easily make that difference.
By the way, I might be able to send you some anonymized aggregated data if you interested in doing some more analysis. Just shoot me an email. However, would appreciate if you don’t crawl the site, because we’re not funded like Strava, and I’m running our poor little servers out of my own pocket.
Smashrun looks like an awesome tool for the goal-oriented runner. Great job with it! I particularly enjoy the rank history chart – feeling the need for something like that. I’ve actually started importing my tracks from Strava (the ability to select multiple files when uploading would surely help people in importing historical data).
The 25th percentile seems about right for me :). I got slightly worse results, but I was also filtering out new (and presumably slower) users. And my one hour time was on flat terrain. I get even more slow when trail running.
Don’t worry, I won’t crawl Smashrun :). I’m thinking of doing some more analyses, but it will be a while until I find the time. That data would sure come in handy (and it would simplify things a lot). I’ll keep this in mind. Thanks 🙂
Very cool. Some of that terrain that your running looks absolutely epic. Envious.
The import via email is the easiest way to get old data into the site right now. You can attach quite a few files to one email, and it makes it much simpler. I’m working on a zip import though, which would make things even easier.
Glad you like the site so far, shoot me an email if you run into any problems.
Pingback: Mining the Strava Data | Oliver Nash's Blog
This is an excellent post, well done!
Just a heads up that I moved my old Strava scraper repo that you used (and linked to) from https://github.com/loisaidasam/stravalib to https://github.com/loisaidasam/stravalib-scraper because I wanted to fork this more fully fleshed out Strava REST API repo https://github.com/hozn/stravalib in a non-confusing way. Do you mind updating the link?
Thanks for the Strava scraping library, Sam! I updated the link.
My pleasure. That new REST API repository for accessing Strava data is pretty awesome as well: https://github.com/hozn/stravalib – definitely worth checking out.
On an unrelated note, I was checking out your Twitter Online Word Graph Summarizer work for that paper you just presented at EACL – very cool! Keep up the good work!
Hello, I am doing some mining on Strava data as well, I just have a question, how did you manage to collect the strava_id of 17000 users?
Hi Luca. I scraped the results from one of Strava’s monthly challenges (such as [1]).
[1] https://www.strava.com/challenges/strava-races-10k-2017-06